MAL Make a Lisp Part 1 Read and Print
Lets keep Lisping!
HI! Hello! Welcome back! If you haven’t read the first part of my journey through making a Lisp using the MAL learning tool then it might make sense for you to start here at the beginning. Unoriginal place to start but the context might help. :)
Pickup where we left off
Part zero was mostly setting up the basic project structure. MAL provides a lot of pseudo end to end tests that are exercised via stdin / stdout. For me to utilise those tests I needed to set up a couple of Makefiles and build scripts.
What I have now is a very simple REPL which when given a string just returns that same string.
+ exec ./gradlew run -q --console=plain --args=step0_repl
Welcome to MAL.
user> This is fun but not super useful!
This is fun but not super useful!
user> exit
exit
Exiting.
Not ground breaking and not very Lispy yet either. Still it is a solid foundation.
Mal Step 1 read and print
My mission for this stage is as follows: From the MAL step one instructions “In this step, your interpreter will “read” the string from the user and parse it into an internal tree data structure (an abstract syntax tree) and then take that data structure and “print” it back to a string.”
Part 1 can be broken down into two major steps, Lexing and parsing. Lexing is a process where a given input is broken down into a series of individual symbols, for example + 123 234 would be transformed into three tokens, +, 123 and 234. Parsing is the process of taking that series of tokens and assembling them into an Abstract Syntax Tree according to the rules of the language.
Neat! This is going to be fun! Lisps are super easy to parse because when you code in Lisp you basically write the abstract syntax tree directly as code. When you open a parenthesis in a Lisp that is the start of a list which corresponds to a node on the AST.
(+ 1 2 (* 2 4))
Would be passed into:
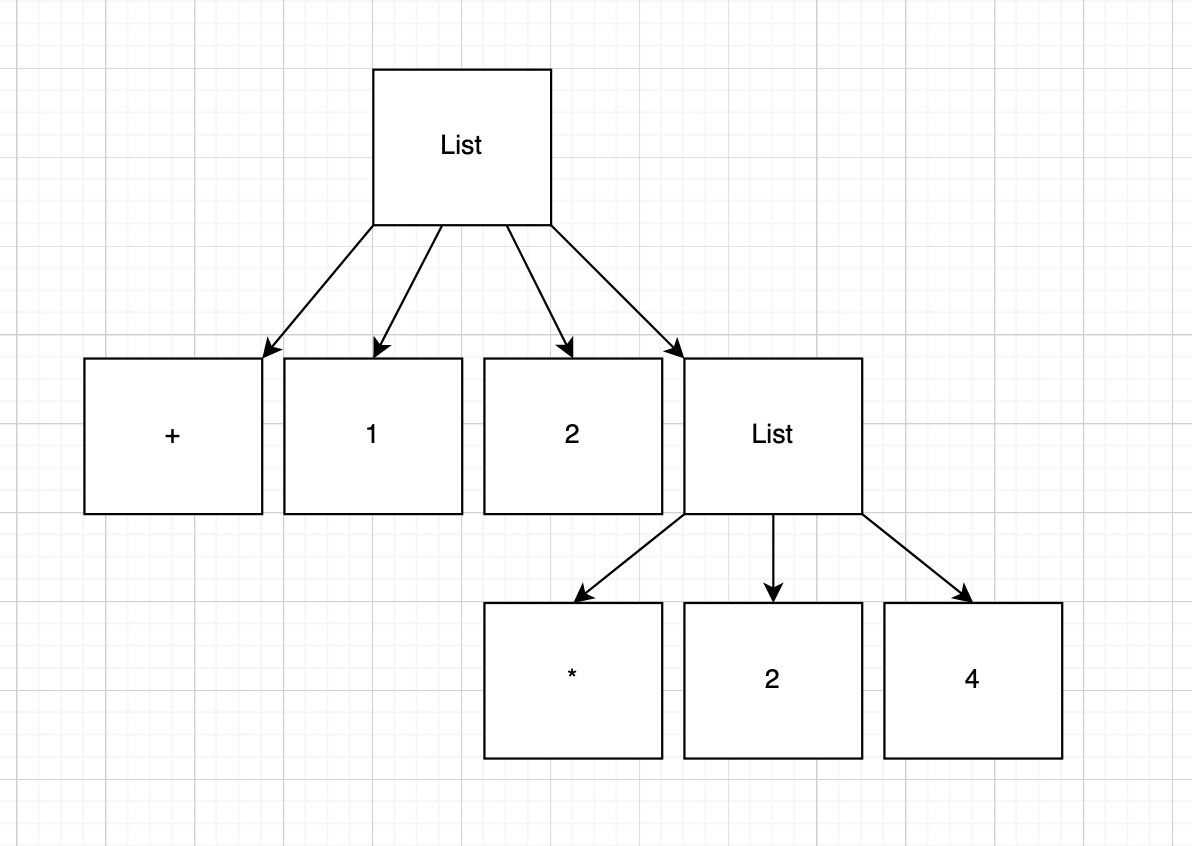
This tree will then be evaluated from bottom to top, but that is for a later task.
Let’s get Lexing!
At the risk of sounding like a broken record, Lisps are syntactically very simple and this makes both Lexing and Parsing fairly simple. The MAL docs provide a single regular expression for the entire Lexing part of this step. For this regex to make sense you need to know Lisp syntax before, specifically knowledge of Clojure will help. This is a bit of shame as it means learning a lot of Lisp upfront instead of learning while we build. I’m going to try and share what is happening with some context as we go.
Personally I’m not a huge fan or massive regular expressions but I’m happy to use it to get moving quickly. I’ve had to tweak the regex very slightly for Java as the Regex given in the instructions was for Perl. Let me try and breakdown the function I’ve written for tokenising input:
public static List<String> tokenize(String input) {
Pattern pattern = Pattern
.compile(
// white space and commas
"[\\s,]*"
// starts a capture group and captures ~@ Special char
+ "(~@"
// any syntax char []{}()'`~^@
+ "|[\\[\\]{}()'`~^@]"
// Open quote until closed quote
+ "|\"(?:\\\\.|[^\\\\\"])*\"?"
// any semicolon and following chars
+ "|;.*"
// // symbols, numbers, "true", "false", and "nil")
+ "|[^\\s\\[\\]{}('\"`,;)]*)";
Matcher matcher = pattern.matcher(input);
// group 1 ignores whitespace and commas
return matcher.results() // Streams
.map(x -> x.group(1))
.filter(string -> !string.isBlank()) // new in java 11!
.collect(Collectors.toList());
}
The first part of this monster regex, "[\\s,]*" matches any whitespace and commas. These will be ignored after this step. In Lisp whitespace is a delimiter between parts of code. For example, items in Java a list are separated by commas while in Lisp the end of one item is marked by whitespace. 1,2,3 vs 1 2 3. Using commas to separate items in a list is stylistic enough that most Lisps allow for that by treating commas exactly as white space.
The next line in the regex opens a capture group. We’re only interested in parts of the input fit the regex in this group. The first token in the capture group is ~@ which in Clojure is a special char for working with macros which is a topic I’m sure we’ll get into later but for now just know we’re capturing it.
Next up is [\\[\\]{}()'`~^@] which will capture a single token from one of the following chars [ ] { } ( ) ’ ~ ^ @. These are all Special Characters and are part of the language syntax. ( for example is the start of a list or a function call.
Strings are captured with "\"(?:\\\\.|[^\\\\\"])*\"?" which captures any input starting with a quote and will stop when it finds an unescaped quote. It will also capture unbalanced strings so we’ll need to add error handling for that at some point.
";.*" will capture any characters starting with a semicolon. In Clojure these represent comments and the MAL Lisp they probably will as well.
The final section, [^\\s\\[\\]{}('\"`,;)]* captures a sequence of non special characters such as symbols, numbers, true, false and nil. For example, this would be captured as seven symbols.
Phew! That is a lot of Regular Expression-ing. I’m almost done with tokenising the input. Everything, apart from the whitespace/commas part of the Regular Expression, was part of a capture group and now I want to return all the matches tokens as a list of Strings. Fortunately, I get my first use of Java Streams in this project!
Matcher matcher = pattern.matcher(input);
// group 1 ignores the whitespace and commas
return matcher.results() // Streams!!!
.map(x -> x.group(1))
.filter(string -> !string.isBlank()) // new in java 11!
.collect(Collectors.toList());
Here, Matcher.results is producing a stream of MatchResult. It lets me map through each result and grab only the parts from the capture group(1). Finally the empty string matches this pattern so I’m filtering it out and collecting the stream into a list of matched Strings. :)
Parsing
Now that I’ve converted an input string into a series of tokens, I need to assemble those tokens into a Syntax Tree as per the MAL instructions. So far I’ve just added support for a subset of all the tokens; Lists, Symbols and Numbers. I’ll add support for other types later on but for now lets take a look.
I’ve stuck very closely to the MAL guide for this section, down to the individual function names. This is because the guide references each of the method names several times and having to swap the guide name into a Java name was just extra work I didn’t want.
Initially I’ve made a Reader class with two properties, a list of tokens from the Lexing section and a position tracker for how far through the list of tokens we’ve processed.
The Reader also has two methods, peek, which returns the token at the current position, and next which returns the token at the current position and increments the position (a side effect ewww).
public class Reader {
private int position;
private List<String> tokens;
public Reader(int position, List<String> tokens) {
this.position = position;
this.tokens = tokens;
}
public String next() {
String token = tokens.get(position);
position++;
return token;
}
public String peek() {
return tokens.get(position);
}
So far so simple. :) Okay, next we need to add four methods, read_str, read_form, read_list and read_atom. read_str is the entry point to this whole Lexing and Parsing section and is called from the REPL class we build in Step Zero. We pass in a raw input String and this method tokenises it, then initialises a new Reader object with the tokenised input and calls read_from. Final point of note, all of these methods return a MalType which is an Interface extended by some data objects. MalNum, MalSym and MalList all extend MalType.
public static MalType read_str(String input) {
try {
List<String> tokens = tokenize(input);
Reader reader = new Reader(0, tokens);
return read_from(reader);
} catch (Exception e) {
return new MalSym("end of input");
}
}
Next up is read_form. This method takes an instance of a Reader, peeks at the current token. If that token is the start of a list, (, then it calls read_list with the Reader otherwise it calls read_atom and increments the current token.
public static MalType read_from(Reader reader) {
char firstChar = reader.peek().charAt(0);
switch (firstChar) {
case '(':
return read_list(reader);
default:
return read_atom(reader.next());
}
}
Then, read_list takes the instance of the Reader and immediately drops the opening ( which started the list. The list will be represented as a MalList Type. read_list then calls read_form until it finds a closing parentheses ) or an Exception is thrown because there are no more tokens to read. Once a closing paren ) has been found it is also dropped from the reader and then we return all the values that were between those parens in a MalList. You can see that read_list and read_form are mutually recursive, they both call each other, this allows for parsing nested lists.
public static MalList read_list(Reader reader) {
// drop leading parenthesis
String token = reader.next();
List<MalType> malTypes = new ArrayList<MalType>();
while (!(token = reader.peek()).equals(‘)’)) {
malTypes.add(read_from(reader));
}
// drop trailing parenthesis
reader.next();
return new MalList(malTypes);
}
Finally we have read_atom which is much simpler. Given a String we need to return an appropriate MalType. Initially I’m just going to handle Symbols and Longs for numbers. This section will grow as I progress through upcoming steps.
public static MalType read_atom(String token) {
try {
return new MalNum(Long.parseLong(token));
} catch (NumberFormatException e) {
return new MalSym(token);
}
}
The try catch is ugly but it works for now. I’ll probably try something a bit more clever when I need to handle more MalTypes… This’ll do for now though.
That is basically it for this stage the only remaining task is to add a MalType Printing class to echo back the AST. As I’ve declared several MalType objects I’ve used their toString methods to define how to print themselves, this makes the Printer class trivial.
public class Printer {
public static String pr_str(MalType malDataStructure) {
return malDataStructure.toString();
}
}
Once we plug this all together and the REPL now we get:
[step1_read_print]
Welcome to MAL.
user> (+ (1 2 3 (- 2 3) (* 2 3)) 234)
(+ (1 2 3 (- 2 3) (* 2 3)) 234)
user> (+ 123
end of input
And that is a wrap for Part 1 read and print. Interestingly I know I’ll need to come back to this part and flesh it out as the Lisp grows more complex. Currently I don’t have Strings, booleans, Maps or Vectors and more. I’d really like to make Reading more functional… maybe it can be made recursive? It was quite fiddly having multiple functions mutate the Reader state.
Thanks for reading! :)